
What the hell is keyword cannibalization?
if you put a lot of articles out there, at some point, some article will compete with one another for the same keywords in Google result pages. it’s what SEO people call ‘keyword cannibalization’.
Does it matter SEO wise?
Sometimes it’s perfectly normal. I hope, for your sake, that several of your webpages show up when someone is typing your brand name in Google.
Sometimes it’s not. Let me give an example:
💭 Imagine you run an e-commerce website, with various page type: products, FAQ’s, blog posts, …
At some point, Google decided to make a switch: a couple of Google search queries that were sending traffic to product pages, now display a blog post of yours.
Inside Google Analytics, SEO sessions count is the same. Your ‘Rank Tracking’ software will not bring you up position change.
And yet, these blog post pages will be able to convert much less, and at the end of the month, this will result in a decrease in sales.
How to check for keyword cannibalization?
There are several ways to do it. Of course, SEO tools people want you to use their tools, the method from ahref is definitely useful. Unfortunately, this kind of tool can be sometimes imprecise, it doesn’t take into account what’s really happening.
So let me show you another method using R’. Once set up, you’ll be able to check big batches of keywords in minutes. 🤖
step 0: install R & rstudio
So, of course, you’ll need to download and install R’ and I’d recommend using rstudio IDE.
There is a lot of tutorials over the Web if you need any help for this part.
step 1: install the necessary packages
First, we’ll load searchConsoleR, awesome 🌈 package by Mark Edmondson.
This will allow us to send requests to Google ‘Search Console API’ very easily.
|
1 2 |
install.packages("searchConsoleR") library(searchConsoleR) |
Then let’s load tidyverse. For those who don’t know about it, it’s a very popular master package that will allow us to work with data frames and in a graceful way.
|
1 2 |
install.packages("tidyverse") library(tidyverse) |
and finally, something to help to deal with Google Account Authentication (still by Mark Edmondson). It will spare the pain of having to set up an API Key.
|
1 2 |
install.packages("googleAuthR") library(googleAuthR) |
step 2 – gather DATA
Let’s initiate authentification. This should open a new browser window, asking you to validate access to your GSC account. The script will be allowed to make requests for a limited period of time.
|
1 |
scr_auth() |
This will create a sc.oauth file inside your working directory. It stores your temporary Access tokens. If you wish to switch between Google accounts, just delete the file, re-run the command and log in with another account.
Let’s list all websites we are allowed to send requests about:
|
1 2 |
sc_websites <- list_websites() View(sc_websites) |
and pick one
|
1 |
hostname <- "https://www.example.com/" |
don’t forget to update this with your hostname
As you may know, Search Console data is not available right away. That’s why we want to request data for the last available 2 months, so between 3 days ago and 2 months before that… again using a little useful package!
|
1 2 3 4 5 6 |
install.packages("lubridate") require(lubridate) tree_days_ago <- lubridate::today()-3 beforedate <- tree_days_ago month(beforedate) <- month(beforedate) - 2 day(beforedate) <- days_in_month(beforedate) |
and now the actual request (at last!)
|
1 2 3 4 |
gsc_all_queries <- search_analytics(hostname, beforedate, tree_days_ago, c("query", "page"), rowLimit = 80000) |
We are requesting ‘query’ and ‘page’ dimensions. If you wish, it’s possible to restrict request to some type of user device, like ‘desktop only’. See function documentation.
There is no point in asking for a longer time period. We want to know if our webpages currently compete with one another now.
rowLimit is a bit of a big random number, this should be enough. If you have a popular website, with a lot of long tail traffic. You might need to increase it.
API respond is store inside gbr_all_queries variable as a data frame.
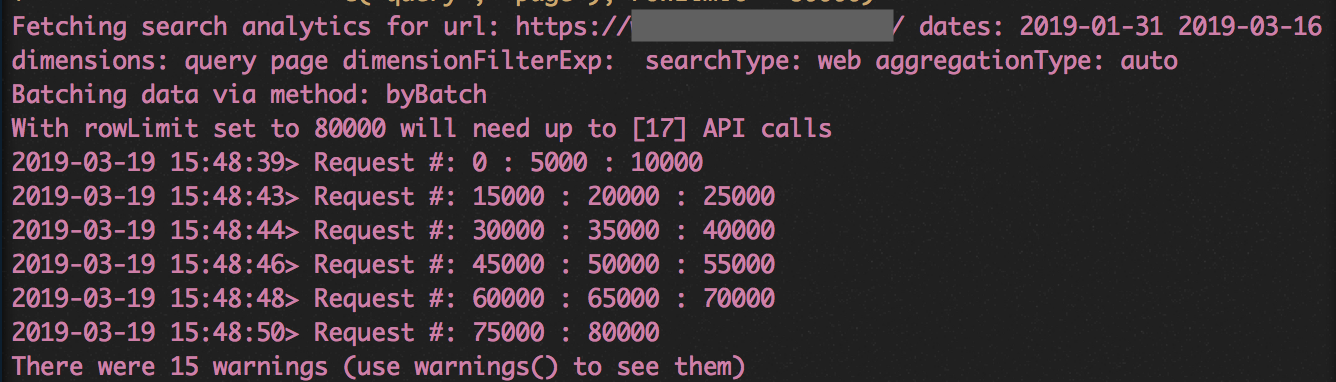
If you happen to have several domains/subdomains that compete with each other for the same keywords, this process should be repeated. The results will have to be aggregated, bind_rows function will help you bind them together. This is how to use it :
|
1 |
bind_rows(gsc_queries_1,gsc_queries_2) |
step 3 – clean up
First, we’ll filter out queries that are not on the 2 first SERPs and that doesn’t generate any click. There is no point of making useless time-consuming calculations.
We’ll also remove branded search queries using a regex. As said earlier, having several positions for your brand name is pretty classic and shouldn’t be seen as a problem.
|
1 2 3 4 |
gsc_queries_filtered <-gsc_all_queries %>% filter(position<=20) %>% filter(clicks!=0) %>% filter(!str_detect(query, 'brandname|brand name')) |
update this with your brand name
step 4 – computations
We want to know for one query, what percentage of clicks are going to each landing page.
First, we’ll create a new column clicksT with the aggregated number of clicks for each search query.
Then, using this value to calculate what we need inside a new per column.
|
1 2 3 4 5 6 7 |
gsc_queries_computed <- gsc_queries_filtered %>% group_by(query) %>% mutate(clicksT= sum(clicks)) %>% group_by(page, add=TRUE) %>% mutate(per=round(100*clicks/clicksT,2)) View(gsc_queries_computed) |
A per column value of 100 means that all clicks go the same URL.
Last final steps, we will sort rows
|
1 2 |
gsc_queries_final <- gsc_queries_computed %>% arrange(desc(clicksT)) |
[edit : ] It could also make sense fo remove rows where cannibalization is not significant. Where per column value is not very high. [end of edit]
Removing now useless columns: click, impression and total click per query group
|
1 |
gsc_queries_final <-gsc_queries_final[,c(-3,-4,-7)] |
Now it’s your choice to display it inside rstudio
|
1 |
View(gsc_queries_final) |
Or write a CSV file to open it elsewhere
|
1 |
write.csv(gsc_queries_final,"./gsc_queries_final.csv") |
Here is my rstudio view (anonymized sorry 🙊)
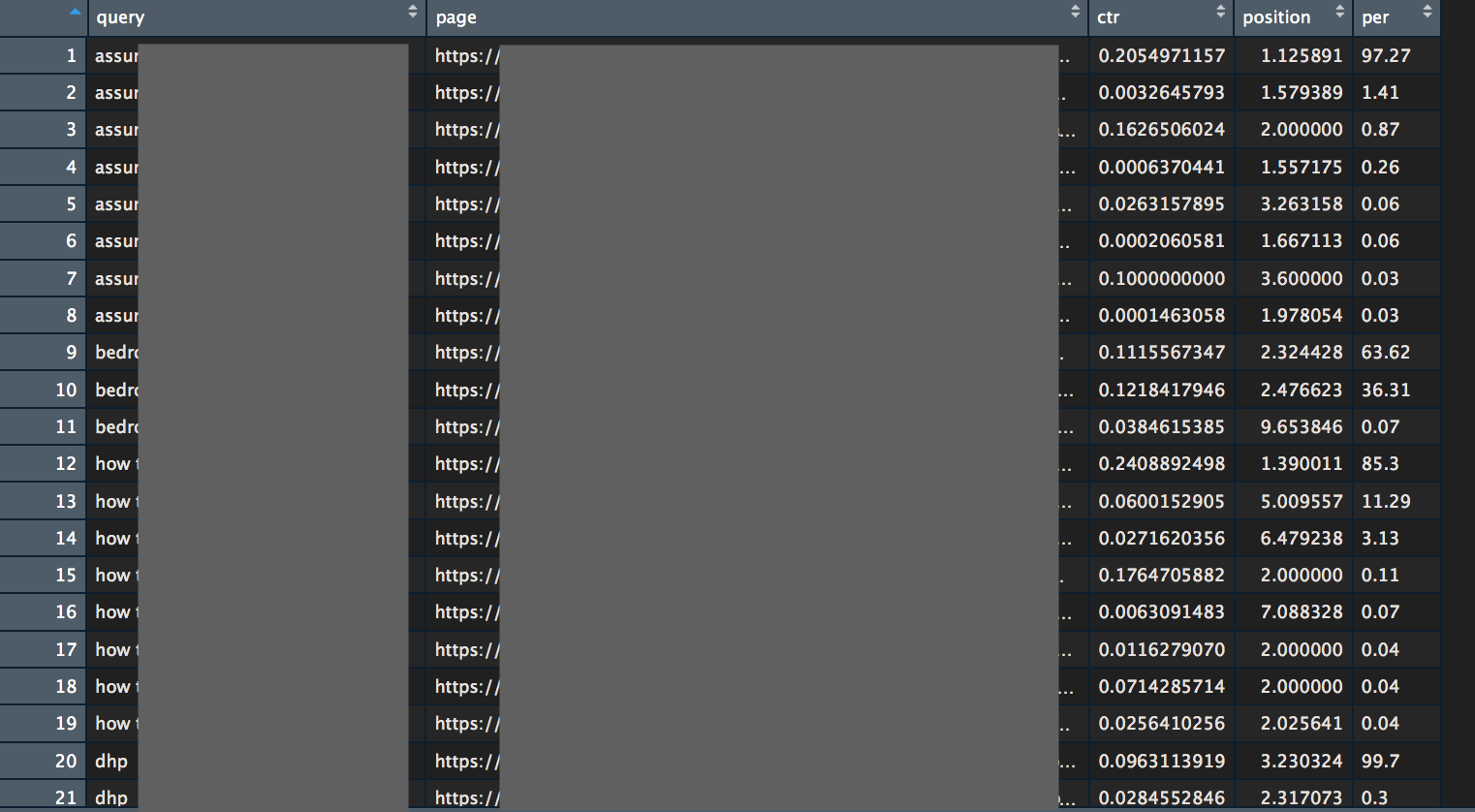
step 5 – analysis
You should check data inside each “query pack”. Everything is sorted using the total number of clicks, so, first rows are critical, bottoms rows not so much.
To help you deal with this, let’s check the first one’s
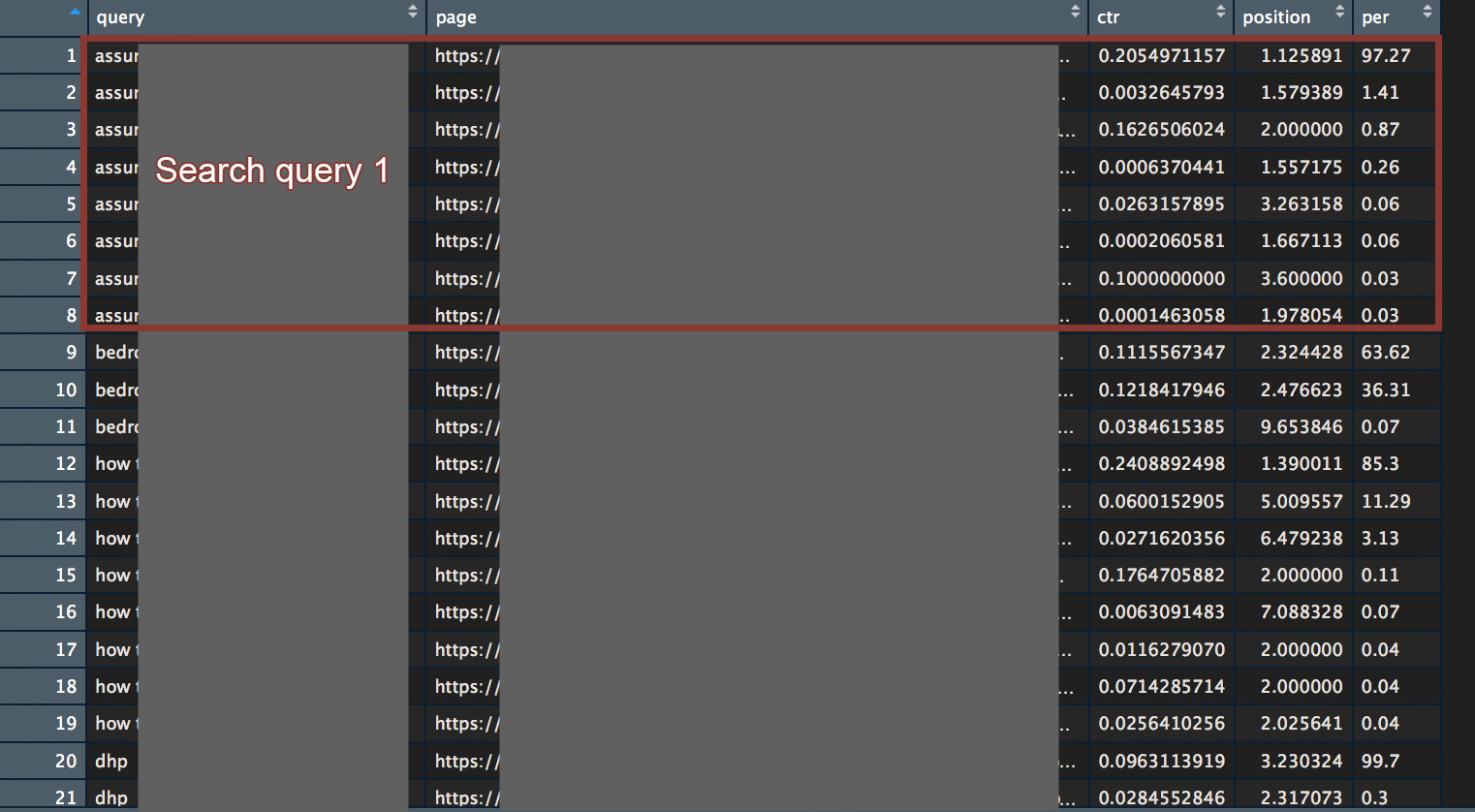
For Search query 1:
97% of click are going to the same page. Their is no Keyword cannibalization here. It’s interesting to notice that the ‘second’ landing page, only earn 1,4% of clicks, even though, it got an average position of 1,5. Users really don’t like the second ‘Langing page’. Page metadata probably sucks.
Check if the first landing page is the right one and we should move on.
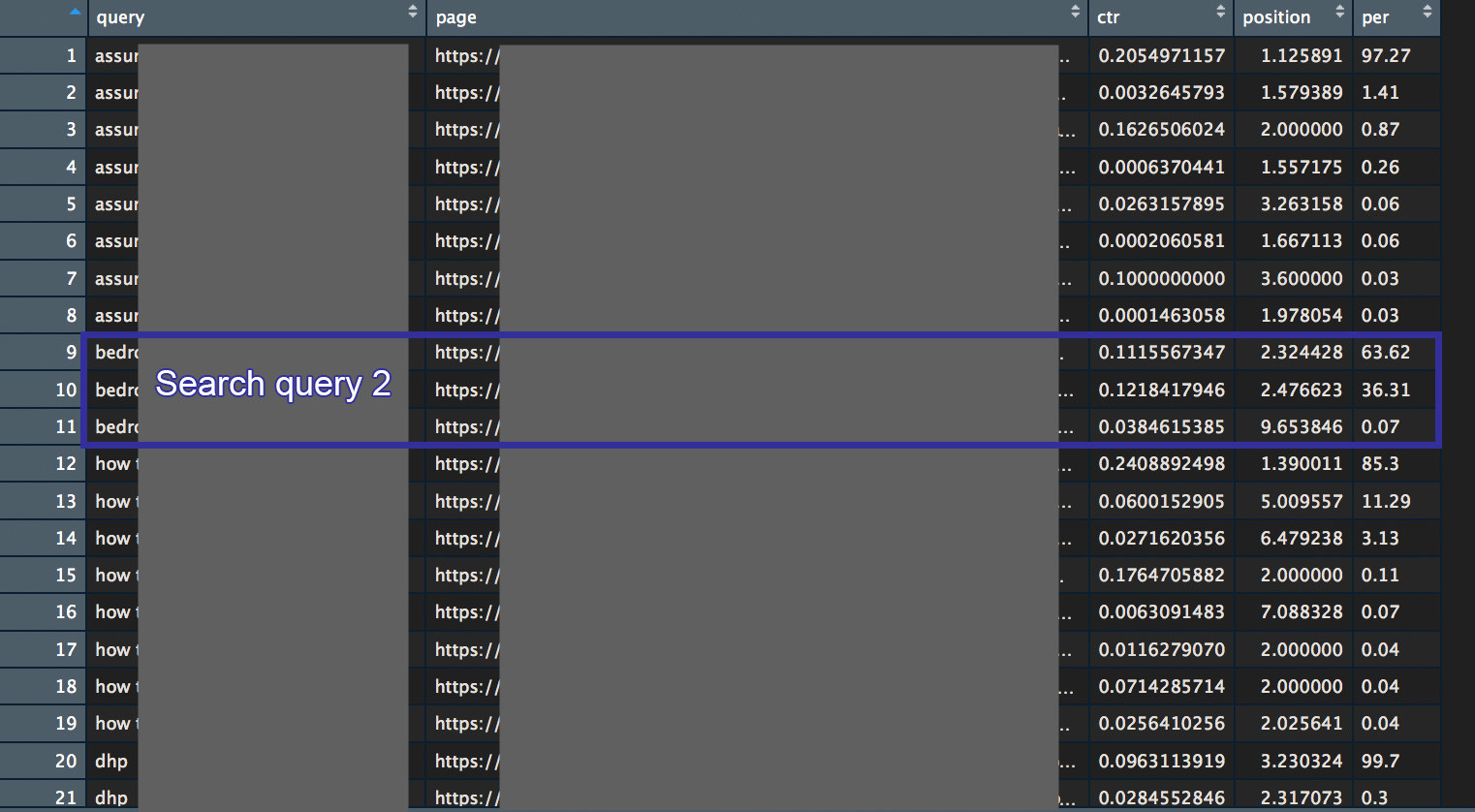
For Search query 2:
63% of click are going to the first landing page. 36% to the second page. This is Keyword cannibalization.
It could make sense to adapt internal linking between involved landing page to influence which one should rank before the other one’s, depending on your goals, pages bounce rates, etc.
And so on…
This is it my friends, I hope you’ll find it be useful!
